- Biweekly Data & Analytics Digest
- Posts
- Why Models Still Hallucinate, How Tech Leaders Measure Success, and Turning Reliability Into a Discipline
Why Models Still Hallucinate, How Tech Leaders Measure Success, and Turning Reliability Into a Discipline
Biweekly Data & Analytics Digest: Cliffside Chronicle
Josh Miramant
24 Sep • Estimated Reading Time: 3 minutes

How Companies Really Measure AI Impact

How do 18 tech firms, including Google, GitHub, Dropbox, and Monzo, measure whether AI coding tools are worth the spend? Mature orgs lean on the same core engineering health metrics as before, PR throughput, change failure rate, cycle time, but also layer in AI-specific lenses like “bad developer days” or “time saved per PR”. What they don’t do is obsess over lines of code generated, a metric boards love but engineers know is meaningless.
This could be the real litmus test for AI in engineering. Does it accelerate velocity without driving up tech debt or tanking quality? That’s where most leaders get tripped up. Tools can make migrations fly, but hallucinated code piles up debt faster than you can ship. Enterprises that already track developer productivity are positioned to measure AI impact effectively. Everyone else is stuck with vanity stats.
If you’re still debating how many lines of code your AI writes, you’re probably not ready to scale it.
Why Models Still Hallucinate (and Why It’s Probably Our Fault)

OpenAI’s latest research explains why LLMs continue to hallucinate, even as models like GPT-5 improve. Yes, you need to train the data, but you also need to know how to evaluate it. Today’s benchmarks reward models for guessing rather than admitting uncertainty. This “accuracy-only” leaderboard means a model that confidently invents a birthday can score better than one that says “I don’t know.”
This is why enterprise adoption of LLMs can be messy. If your evals optimize for bravado over humility, you’ll deploy systems that are persuasive but wrong. That’s a governance and trust nightmare. The fix is to redesign scoreboards to penalize confident errors more than abstentions.
Without shifting eval culture, the “trustworthy AI” messaging might not be as accurate as we’d like to believe.
How Databricks Scales Database Reliability Without Adding Overhead
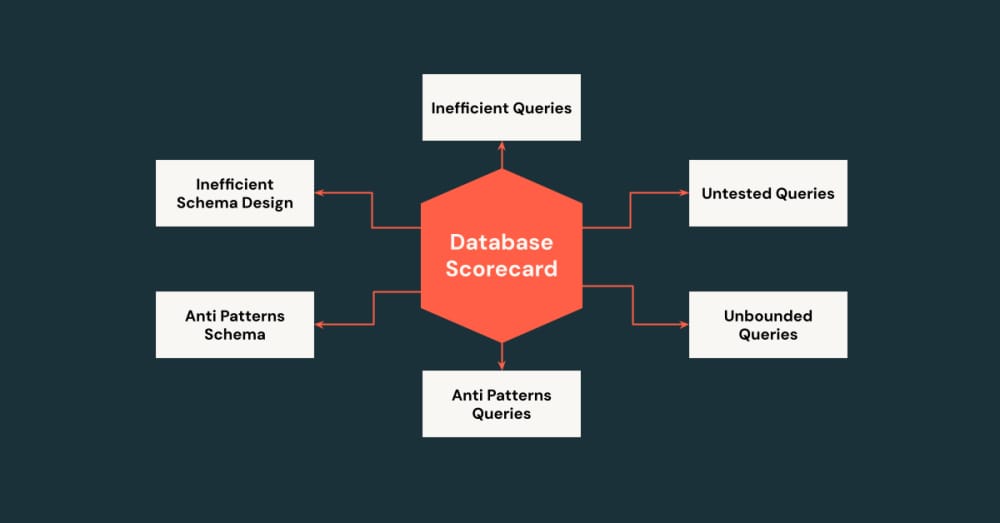
Databricks scaled reliability across thousands of internal databases by flipping from reactive monitoring to proactive scoring. Instead of waiting for query spikes or lock contention to trigger incidents, they now pipe query logs into Delta Tables, score queries in CI pipelines, and surface everything in a Database Usage Scorecard. The results are tangible. Databases sustaining 4x traffic while consuming fewer resources.
This is a template for anyone wrestling with OLTP reliability at scale. Traditional server-side monitoring only catches pain once users feel it. Databricks shows how analytics-native pipelines can enforce best practices before incidents land. The strategy (trace at the client, aggregate in Delta, automate checks in CI) isn’t unique to Databricks, but their stack makes it seamless.
If you’re still fighting fires with dashboards, you need to build reliability into the dev loop itself.
Secure Data Access Is the Hard Part of LLM Adoption
Snowflake lays out a pragmatic security checklist for integrating enterprise data with LLMs: authentication, RBAC, encryption, zero-trust networks, compliance frameworks, and incident response. These controls are built into Cortex AI’s security perimeter, letting teams plug in models from OpenAI, Anthropic, or Mistral without needing to build bespoke security scaffolding for each integration.
The dirty secret is most proofs of concept skip serious security setup, which creates pipelines that can leak sensitive data in a single misconfigured API call. Snowflake’s pitch is compelling (governance-first integration without slowing down dev teams) but it also signals the bar is rising.
The real takeaway is that security is the foundation.
The Subagent Era: Breaking Down Monolithic AI

There’s a growing shift towards subagents in AI architecture. Instead of one all-purpose agent juggling dozens of tools, focused specialists each have its own isolated context and task. Explicit subagents (like Claude Code’s reviewers) are reusable and predictable, while implicit ones spin up dynamically for one-off goals. Both approaches tackle the Achilles’ heel of monolithic agents: context pollution.
This direction is inevitable for enterprises trying to operationalize agentic AI. Just as microservices replaced monoliths in software, subagents promise scalability, reliability, and testability. But there is a tradeoff: control vs. flexibility. Static subagents give security and predictability, while dynamic ones risk chaos if orchestration fails.
For data teams, orchestration and model quality will determine success.
MIT’s Playbook for Smarter LLM Training

MIT and IBM researchers just dropped the largest meta-analysis yet on scaling laws, studying 485 models across 40 families to test how well small-model results predict big-model performance. Their findings: scaling laws can cut training waste dramatically by including intermediate checkpoints, discarding noisy early-token data, and mixing in models of varied sizes. Done wrong, they mislead teams into burning millions.
The research shows they’re only as good as the methodology. For mid-market teams priced out of GPT-scale budgets, this could be the difference between running a smart $2M experiment vs. a sunk-cost disaster.
Scaling laws are operational strategy, so it’s time to stop looking at them as theory.
Blog Spotlight: Llama 2: Generating Human Language With High Coherence
From cloud data platforms like Snowflake and Databricks to AI agents, analytics, CRM, and collaboration software, this article lays out how the right tools unify fragmented operations and turn them into real-time, insight-driven systems. Success comes from aligning the right tools with business objectives and measuring tangible outcomes. For mid-market leaders, digital transformation is the operating system of modern business.
“Data is a precious thing and will last longer than the systems themselves.”