- Biweekly Data & Analytics Digest
- Posts
- The New Rules of Model Efficiency, Data Engineering’s Reinvention, and the Rise of AI Orchestrators
The New Rules of Model Efficiency, Data Engineering’s Reinvention, and the Rise of AI Orchestrators
Biweekly Data & Analytics Digest: Cliffside Chronicle
Josh Miramant
05 Nov • Estimated Reading Time: 4 minutes

The Next Frontier of AI Isn’t Building Models, It’s Measuring Them

Without rigorous, repeatable testing, model development is guesswork dressed up as innovation. The piece lays out a systematic framework for evaluating large language models, from automated metrics like BLEU and perplexity to human-in-the-loop assessments that capture nuance and bias. It also highlights the growing role of domain-specific evals (like SQL generation accuracy or reasoning under data constraints) showing that one-size-fits-all benchmarks are increasingly obsolete. In short, evaluation should be a continuous, data-driven feedback loop, not a one-time event.
Reliable evaluation is now the backbone of responsible deployment (especially as enterprises move from fine-tuning foundation models to customizing smaller, domain-trained ones). Databricks’ approach aligns with what we’re seeing across mature data teams: treat evaluation as an engineering discipline, with standardized pipelines, reproducible datasets, and clear metrics for success.
The next generation of AI success stories won’t hinge on who trains the biggest model, but on who measures best.
Bigger Is Just More Expensive, Not Better

LLM performance doesn’t scale linearly with model size or dataset volume. Based on recent research on scaling laws and compute optimization, the ideal model isn’t the largest one your GPUs can handle, it’s the one that delivers maximum accuracy per dollar. The article walks through the trade-offs between model parameters, dataset size, and training cost, illustrating how fixed compute budgets demand smarter resource allocation. In practice, this means finding the “sweet spot” where additional data boosts quality more efficiently than adding more parameters (a surprisingly small model can outperform a giant one if trained strategically).
This research gives data leaders a framework for justifying smaller, more specialized models (something CFOs love and MLOps teams desperately need). We’re movings towards budget-aware model selection where smart scaling beats brute force.
As inference costs climb and context windows expand, efficiency is no longer optional, it’s the new competitive edge.
That Data Engineer Is Dead. Long Live the Data Engineer.

Snowflake’s latest post reframes the data engineer’s evolution as both a technical and strategic shift. The traditional pipeline-focused role (ETL, warehousing, orchestration) is being replaced by a new breed of engineer fluent in data contracts, observability, and AI readiness. Modern engineers are focusing on platform design, governance, and model enablement. Snowflake positions this as an inevitable progression driven by the convergence of data and AI platforms like Snowflake Cortex, Databricks Mosaic AI, and Microsoft Fabric (where engineers now serve as the connective tissue between analytics, MLOps, and business outcomes).
Data engineering is becoming a product discipline, not a service role. The engineers who thrive are the ones who design reliable data systems, not one-off pipelines. This evolution matters for mid-market teams (especially where headcount is tight and impact is measured in throughput and time-to-insight). Tools like dbt, Delta Live Tables, and Snowflake’s native ML features are collapsing the distance between raw data and usable intelligence.
The “data plumber” era is over. The new data engineer looks more like a platform strategist: balancing governance, automation, and the demands of AI-driven analytics.
The Hidden Layer Powering the Next Wave of AI Agents

Orchestrators like LangGraph, CrewAI, and Semantic Kernel act as the control plane for complex, multi-agent workflows (handling context, tool usage, memory, and inter-agent communication). As LLMs move from static chatbots to autonomous systems that call APIs, write code, or query databases, orchestrators are what make them reliable and repeatable. The piece outlines how these frameworks differ from simple prompt chains or RAG pipelines: they add real state management, observability, and reasoning orchestration, enabling agents that can coordinate like software, not scripts.
Without orchestration, it’s chaos: an expensive mess of API calls and hallucinations. The orchestration layer is where AI becomes operationally useful. Think of it as the Kubernetes moment for LLM systems (abstraction, scheduling, and lifecycle management for intelligent processes). For mid-market data leaders, this means AI won’t just be embedded in apps. It’ll soon be managing your workflows, retraining models, and running ETL logic dynamically.
The real challenge is standardization. Right now, it’s a Cambrian explosion of frameworks, not an ecosystem.
The Subtle Poison in AI Data: Why Small Samples Can Break Big Models
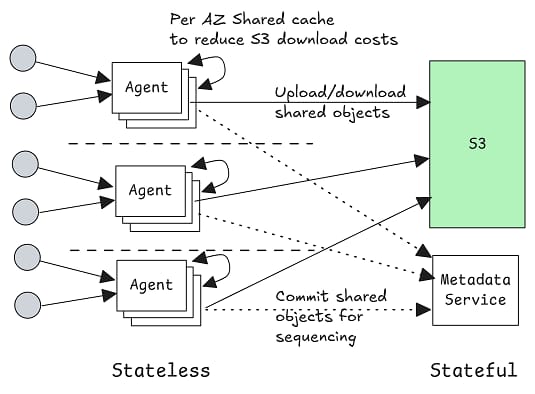
Jack Vanlightly’s deep dive into Kafka’s potential “diskless” future exposes a rift at the heart of modern data infrastructure. The debate: should Kafka ditch its traditional log-on-disk model for a fully in-memory, ultra-low-latency design? The argument for going diskless centers on speed (cutting I/O overhead to rival real-time messaging systems like NATS or Redpanda’s memory-first modes). But the tradeoffs are severe: lose disks, and you lose persistence, replayability, and auditability (aka. the very things that make Kafka foundational in data ecosystems).
This isn’t just a Kafka debate. It’s a philosophical fork for data engineering. Do we want our streaming platforms to act more like caches (fast, ephemeral, transient) or databases (durable, replayable, verifiable)? A diskless Kafka might fit some edge or ML scenarios, but for most enterprises, durability is non-negotiable. Still, the conversation signals where performance pressure is heading: toward memory-first architectures that challenge decades of data storage assumptions.
Kafka’s future will test how far we’re willing to go to trade reliability for real-time.
RL Finds Its Own Scaling Laws (and a New Playbook for AI Training)
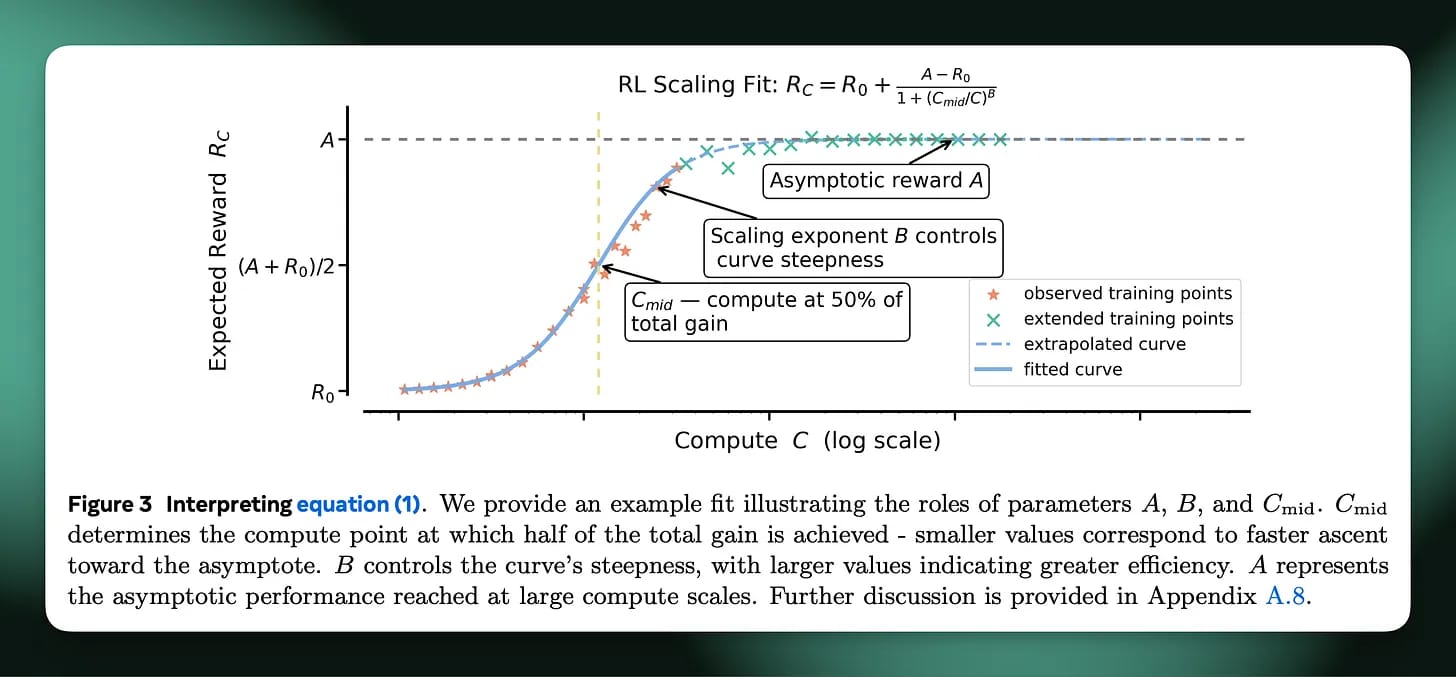
This piece dives into a new wave of research showing that RL (long seen as too unstable or data-hungry for large-scale use) is finally discovering its own scaling laws. Similar to what we’ve seen in LLM training, researchers are identifying predictable relationships between compute, model size, and performance in RL systems. This could make training agents (for reasoning, planning, or simulation) far more systematic, replacing the trial-and-error chaos that’s defined RL for years. The article traces how structured exploration strategies and improved synthetic data generation are helping RL catch up to supervised learning in scalability and predictability.
Scaling laws brought order to LLMs, and now they’re coming for RL. This means future AI systems might not just predict language. They could plan, experiment, and adapt with measurable efficiency. It also underscores why compute strategy matters as much as model architecture.
For data teams building simulation-driven or agentic systems, this research hints at a coming era where reinforcement pipelines become as tunable and budget-aware as LLM fine-tuning.
Blog Spotlight: Transform Your Business Intelligence with Strategic Data Integration
The real differentiator in analytics today isn’t just visualization or tooling. It’s how intelligently your data ecosystem is stitched together. The article makes a compelling case for strategic integration as the backbone of effective BI, showing how unified, well-modeled pipelines enable real-time insights, reduce redundancy, and unlock AI-driven analytics. What resonates most is the shift from integration as a technical chore to integration as a strategic enabler (a force multiplier for decision-making, speed, and scale).
“The goal is to turn data into information, and information into insight.”