- Biweekly AI, Data & Analytics Digest
- Posts
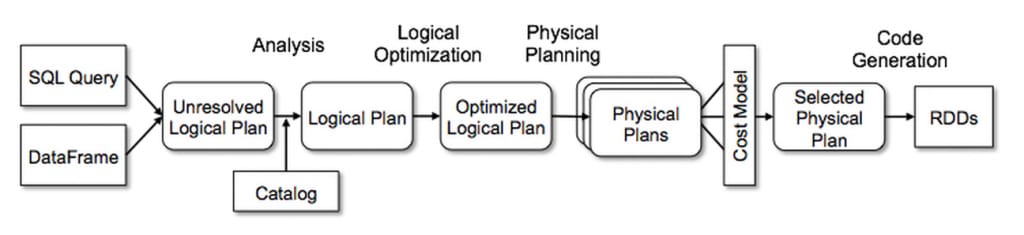
- Postgres Reimagined, Spark Reconsidered, and LLM Risks and Limitations
Postgres Reimagined, Spark Reconsidered, and LLM Risks and Limitations
Biweekly Data & Analytics Digest: Cliffside Chronicle
Josh Miramant
02 Jul • Estimated Reading Time: 4 minutes

Postgres Gets a Makeover with Decoupled Compute and storage, and It’s a Big Deal

PostgreSQL is entering the cloud-native arena. New contenders like Neon (acquired by Databricks) and Crunchy Data (acquired by Snowflake) are rebuilding Postgres with a decoupled architecture: separate compute and storage, high concurrency, fast branching, and elastic autoscaling. It’s still “Postgres,” but under the hood, these vendors are reconstructing core layers like WAL handling and storage indexing to make it truly cloud-first.
This signals a shift that transactional databases are finally getting the architectural innovation that analytics platforms like have been riding for years. This signify a pivotal shift in data architecture, unifying transactional (OLTP), analytical (OLAP), and AI workloads within a single platform. By integrating PostgreSQL—renowned for its open-source flexibility and extensive ecosystem—both companies aim to eliminate traditional data silos. Databricks leverages Neon’s serverless, AI-optimized architecture to support rapid, ephemeral database provisioning, catering to the dynamic needs of AI agents. Conversely, Snowflake incorporates Crunchy Data’s enterprise-grade, FedRAMP-compliant PostgreSQL to bolster its AI Data Cloud, ensuring secure and scalable transactional capabilities. These strategic moves underscore a broader industry trend towards converged, AI-ready data infrastructures that prioritize openness, scalability, and developer-centric design.
Spark’s Performance Problems Are Often Misunderstood , and Very Fixable
Sem Sinchenko offers a thoughtful breakdown of the common perception that “Spark is slow.” The reality is more nuanced. Spark’s distributed architecture, with features like lazy evaluation, stage-based DAG execution, and shuffle operations, provides immense flexibility and scalability, but also introduces complexity. Many of the bottlenecks teams face stem from suboptimal job design: excessive shuffling, inefficient joins, poorly sized partitions, or unoptimized UDFs. Sinchenko highlights that Spark isn’t inherently slow. It just demands that you understand how it works to get the most out of it.
This is a great reminder that Spark rewards expertise. Teams unlock serious performance gains with small architectural changes: caching smartly, tuning parallelism, and leaning into native functions instead of UDFs. With Databricks’ Photon engine accelerating critical paths under the hood, Spark continues to evolve for performance-hungry workloads. Compared to simpler engines like DuckDB or BigQuery, Spark still shines when you need scale, flexibility, and fine-grained control, especially in complex pipelines and AI/ML workflows.
LLM Security: 6 Risks No One Talks About (But Should)

Critical security risks are lurking in LLM deployments, especially for teams integrating them into production systems. The threats go beyond prompt injection: we're talking data leakage through model outputs, training data exposure, supply chain vulnerabilities in open-source models, insecure API integrations, and even model-based denial-of-service risks. Traditional app sec practices fall short when applied to probabilistic systems like LLMs, and platform engineers need new playbooks to monitor and govern AI behavior in the wild.
Most mid-market teams racing to embed LLMs into workflows are treating them like APIs rather than potentially unbounded compute agents with access to sensitive data. Test prompts can accidentally expose internal PII, or where latency gets crushed by unbounded context windows. Even tools like LangChain and RAG pipelines, which are now considered “standard”, can introduce new risk surfaces.
Unlike typical apps, LLMs don’t have fixed behavior, which means security must shift from static rules to dynamic monitoring and control. Vendors are starting to bake in more guardrails, but the operational burden still lands on the platform team.
Just Because Your Model Accepts 100K Tokens Doesn’t Mean It knows What To Do With Them
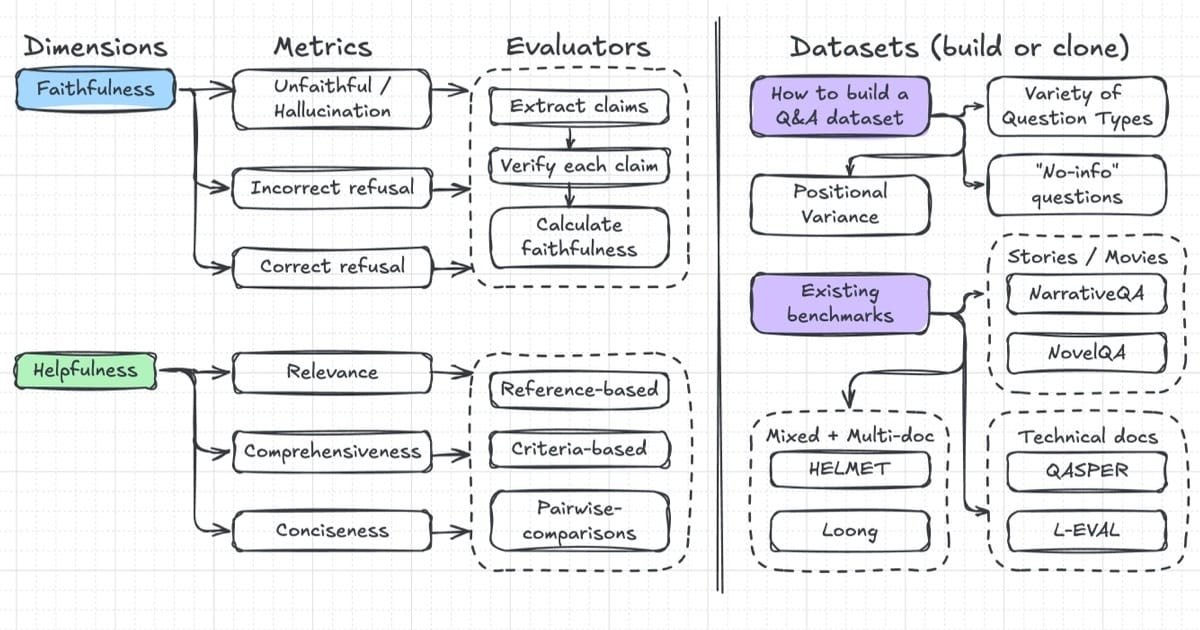
There are surprising limits of long-context LLMs when it comes to question answering over large documents. Despite massive context windows, many models struggle with retrieval, relevance, and reasoning across distant parts of a document. This article highlights three evaluation strategies, retrieval-based (can it find the info?), reasoning-based (can it infer answers?), and end-to-end QA, to show where things fall apart.
More tokens ≠ better performance. In some cases, smaller context plus smart chunking or RAG outperforms brute-force context stuffing.
This hits close to home for teams building knowledge assistants, summarization tools, or search copilots. Some clients assume longer contexts would eliminate the need for chunking or retrieval. But the truth is that model attention degrades with scale, and token sprawl introduces noise. Even Claude 3 and GPT-4o don’t “read” the full context; they just weigh parts of it better. So the real challenge is less about how much context you can pass, and more about how effectively you guide the model’s attention.
How to Actually Evaluate Agentic AI in the Enterprise
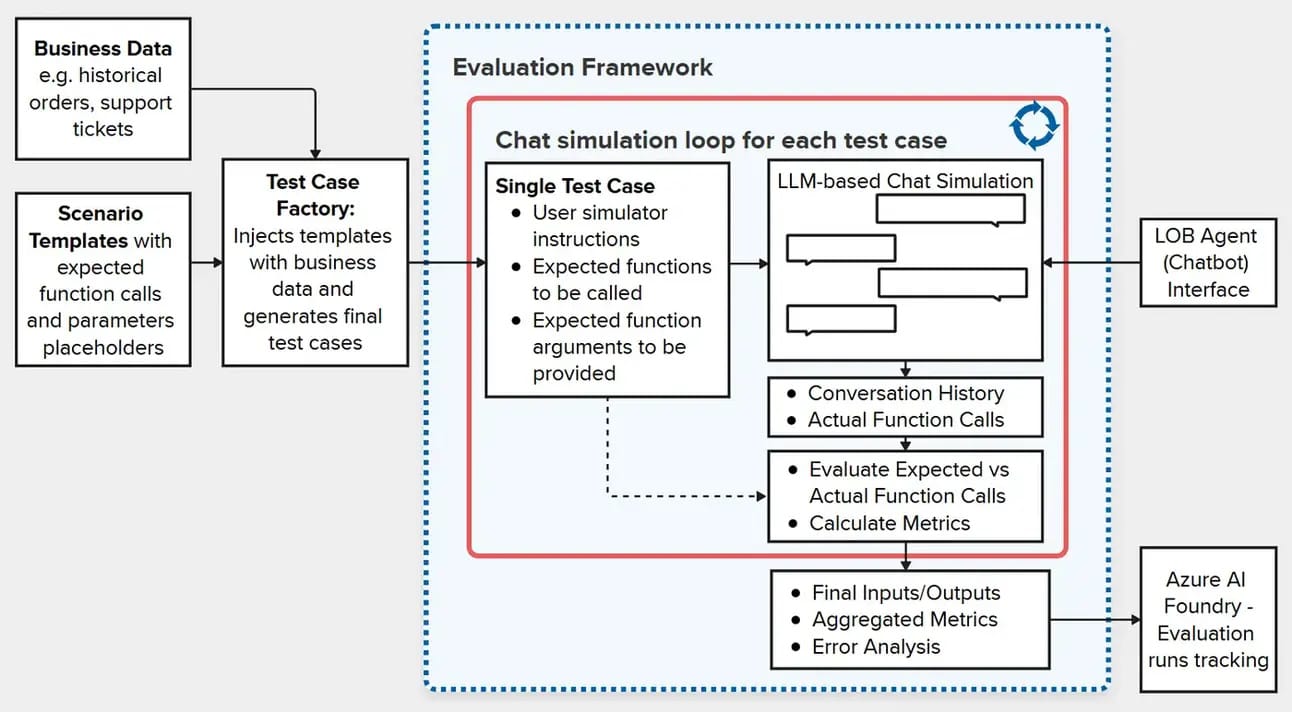
Traditional metrics like accuracy or BLEU scores don’t cut it when agents are making decisions, calling APIs, or driving workflows. Instead, the authors introduce a three-part evaluation framework: Correctness (does the agent fulfill the task), Coherence (is the interaction understandable and useful), and Coverage (does it handle the full scope of expected use cases). Importantly, the framework blends automated metrics with human-in-the-loop review to strike a balance between scale and judgment.
This is a key read for any data or platform team building AI copilots, workflow agents, or internal chatbots. We’ve seen too many teams ship agentic systems with vague success criteria — and get blindsided when users stop trusting them after a few fumbles. What’s refreshing here is the shift away from “perfect response” metrics to something closer to user trust and task completion. It also reflects the growing reality that AI evaluation is as much a product problem as a model problem. Databricks and other MLOps platforms are starting to adopt similar thinking in their eval stacks.
Building AI That Remembers: Why Long-Term Memory Is the Next Frontier
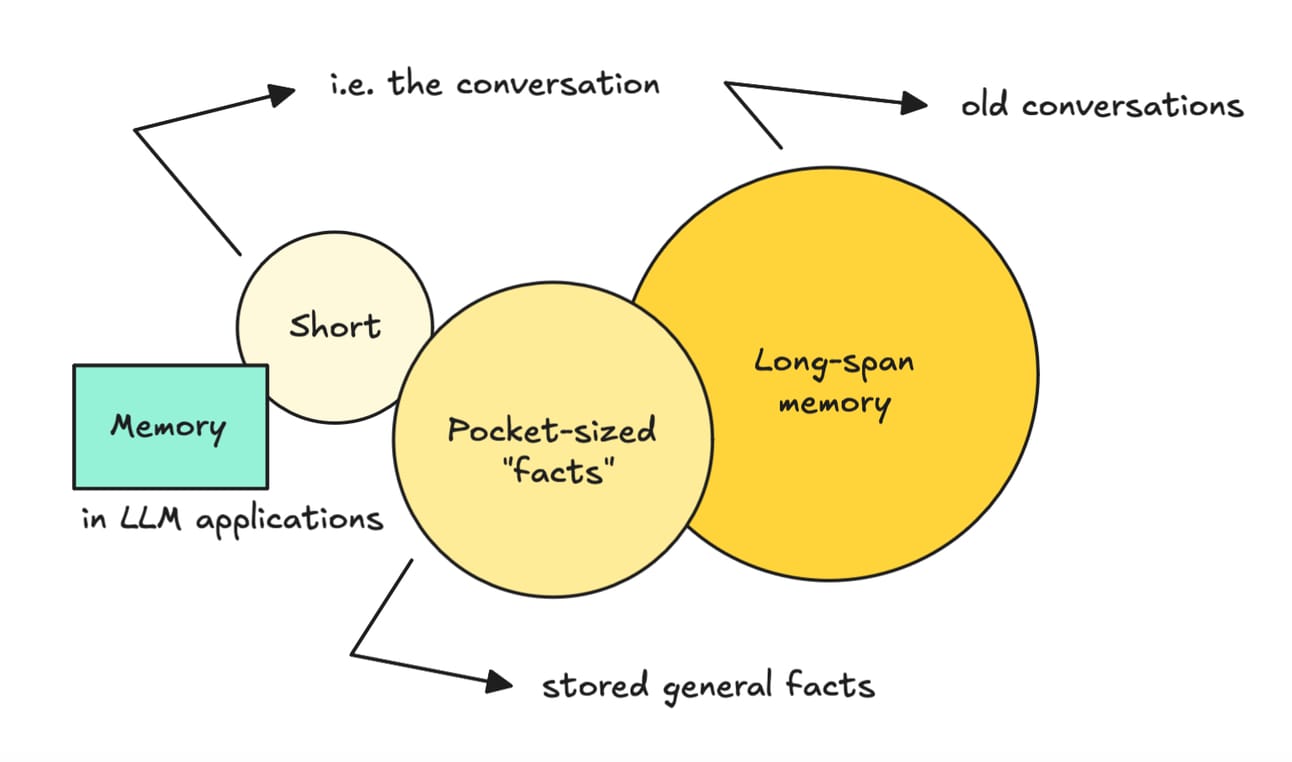
Long-term memory is being implemented in agentic AI systems, an it’s changing the landscape. Unlike typical LLM apps that forget everything between sessions, memory-equipped agents can store, retrieve, and reason over accumulated knowledge, which enables more coherent, goal-driven behavior over time. The article outlines a memory architecture using vector stores (like FAISS or Weaviate), embedding-based recall, and summarization loops to capture and re-surface relevant context. It also touches on tools like LangChain and LlamaIndex that simplify this workflow, and the tradeoffs between episodic memory (what just happened) vs. semantic memory (what matters long-term).
This is a big deal. Lack of memory kills trust and usefulness in enterprise AI assistants. Agents that forget user context or repeat past mistakes feel brittle. Long-term memory changes the UX: it enables personalization, task follow-through, and real collaboration. But it also adds complexity, from memory bloat to retrieval noise to prompt injection risks.
Blog Spotlight: Unified AI Workflows: Accelerating End-to-End GenAI Projects with Databricks
Databricks’ Unified AI Workflows offer a structured, end-to-end approach to GenAI development by integrating data engineering, model training, vector search, and LLM deployment within the Lakehouse platform. Tools like MLflow, Mosaic AI, and Unity Catalog can streamline pipeline complexity, reduce context switching, and provide governance for everything from RAG systems to custom LLM apps. For mid-market teams, this unified stack means faster time to value and fewer integration headaches, which is critical as GenAI moves from proof-of-concept to production.
“Data without metadata is like a supermarket full of tins with no labels.”