- Biweekly AI, Data & Analytics Digest
- Posts
- Context Is King, GenAI Is Hungry, and Chatbots Are Unemployed
Context Is King, GenAI Is Hungry, and Chatbots Are Unemployed
Biweekly Data & Analytics Digest: Cliffside Chronicle
Josh Miramant
16 Jul • Estimated Reading Time: 4 minutes

GenAI Is Forcing a Rethink of the Data Lake

The data lake was never designed for this. Unlike analytics workflows that rely on structured, batched, and governed data, GenAI thrives on messy, unstructured, real-time information like PDFs, emails, Confluence pages, and customer chats. The pipelines, governance layers, and latency-tolerant design of the data lake are clashing hard with LLMs’ demand for flexible, high-context, real-time inputs. As much as we wish this was only a minor architectural tweak, it’s actually a divergent use case demanding new tooling, new processes, and a total mindset shift.
Teams try to duct-tape RAG or fine-tune workflows onto warehouses built for BI, then wondering why hallucinations and latency issues pile up. The fact is, GenAI doesn’t care about your clean tables or dbt models. It wants your SharePoint, but that requires a different approach to ingestion, indexing, security, and retrieval. As a result, tools like LangChain, Weaviate, or LlamaIndex are emerging not as add-ons, but as foundational components.
This divergence means architecture leaders need to decouple their GenAI strategy from their BI stack, or risk both collapsing under the weight of mismatched expectations.
Forget Prompt Engineering: Context Engineering Is the Real Skill for GenAI
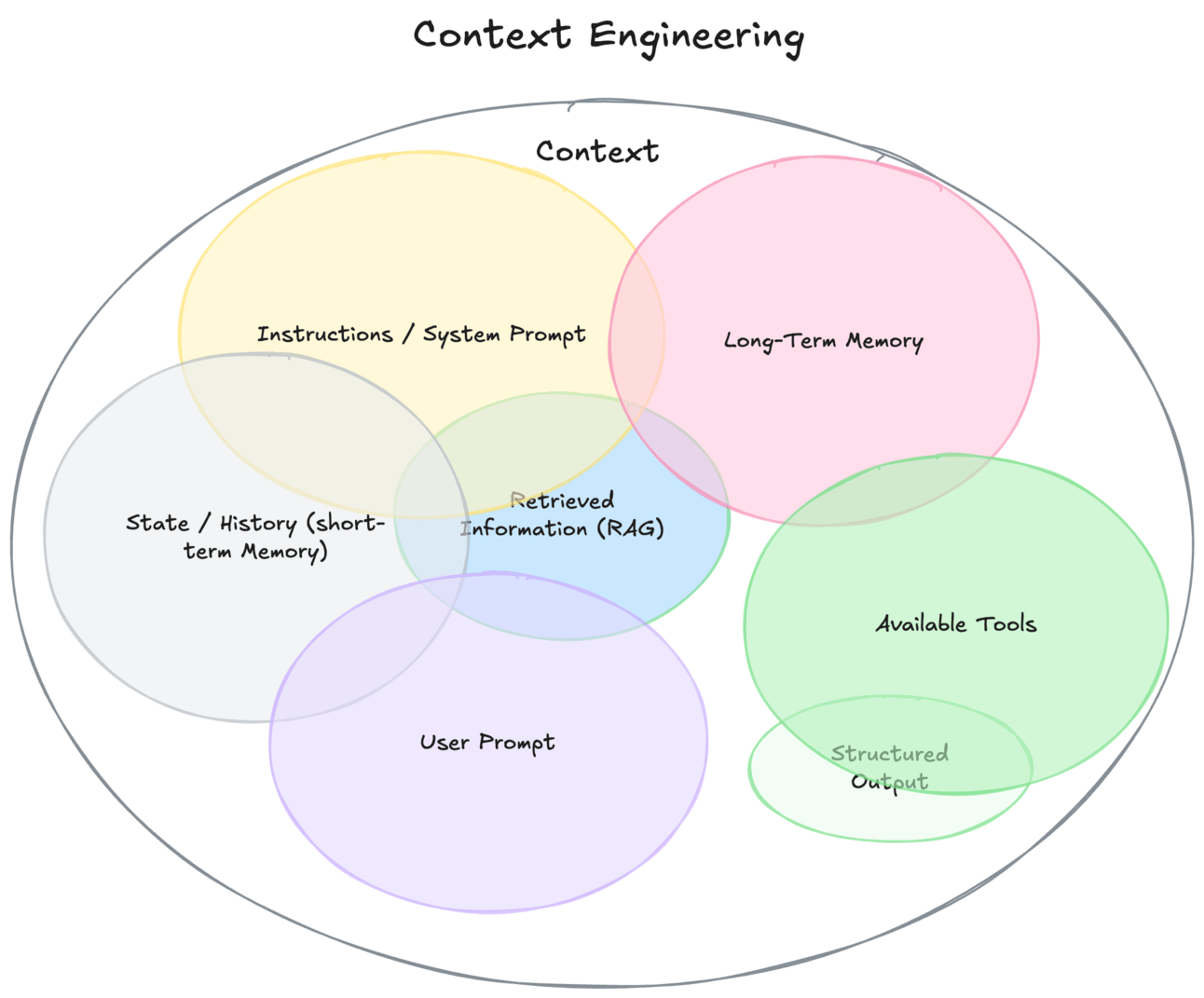
“Prompt engineering” is a shallow framing for what actually drives performance in real-world LLM apps. The real challenge is context engineering: the art and science of giving the model the right data, in the right format, at the right time. That includes chunking, ranking, summarizing, embedding, compressing, and routing context across multiple sources, which is far more than work than slapping a clever prompt on top. In production-grade RAG systems, most performance gains come not from tweaking prompts, but from fine-tuning how relevant business context is retrieved and fed into the model.
There is a dangerous overreliance on prompt templates, while teams overlook the actual content and quality of context they’re retrieving. A flashy frontend doesn’t fix bad chunking, vector noise, or brittle retrieval logic. Context engineering is closer to traditional data engineering than prompt fiddling, and it needs the same level of rigor. This changes who you need on your team, how you evaluate LLM quality, and what your architecture looks like. Stack choices like LlamaIndex vs. LangChain, hybrid vs. dense retrieval, or pre-processing with sentence transformers are now becoming strategic decisions rather than implementation details.
The next generation of GenAI apps will be won not by better prompts, but by better pipelines.
Data Industry Fatigue and What Comes Next

Joe Reis unpacks a sentiment many in data quietly share: burnout, disillusionment, and the constant churn of overhyped trends. From the fall of the Modern Data Stack narrative to the rise (and likely fall) of GenAI hype, Reis argues that the data world is stuck in a loop of inflated expectations and inevitable disappointment. But beneath the exhaustion is a subtle optimism, and a call to refocus on solving actual problems with less noise, fewer buzzwords, and more humility.
This plays out inside teams with overbuilt stacks, underwhelming impact, and leadership asking, “Why are we spending so much for so little?” Reis puts a name to that fatigue and offers a mindset shift. We don’t need more tools. Instead, we need to focus on building boring, durable systems that solve real needs.
If you’re a technical leader, this a moment to pause and reflect on whether you’re building momentum or just motion.
From Talk to Action: Why AI Agents Beat Chatbots Every Time
The real value in AI isn’t chat. Instead of building generic chatbots that mimic conversation, teams should design autonomous agents with specific jobs and clear goals. Think: a report generator that emails your weekly KPIs, not a bot that vaguely “talks about data.” LLMs can be embedded into workflows where they perform tasks, make decisions, and call functions, which is a far cry from the passive Q&A experiences most companies are deploying.
Too many orgs waste cycles (and budgets) building flashy chat interfaces that ultimately get ignored by users. Here’s the truth: talking to a bot isn’t useful unless it does something valuable. The shift to job-based agents aligns with how tools like LangGraph, CrewAI, and OpenAI functions are evolving towards composable workflows where LLMs act as collaborators rather than responders. This forces clearer thinking around scope, responsibility, and evaluation, which is much needed in a space still obsessed with “chat UX.” And it plays better with enterprise systems, where APIs and automation matter more than cute dialogue.
If your GenAI app doesn't do a job, it's probably not worth building.
Are We Overthinking Data Products? (We Probably Are)

Have we overcomplicated something that should be simple? “Data product” initiatives often balloon into over-engineered, process-heavy frameworks that lose sight of the original intent: delivering usable, valuable data to end users. Instead of checklist-driven data contracts and overly formalized productization, the focus should be on collaboration, context, and trust. A good data product isn’t defined by how closely it adheres to some canonical spec. It solves a real problem.
In mid-market orgs, data teams can chase “data product” dogma without the headcount, governance maturity, or demand to justify it. You don’t need a data mesh to deliver reliable tables. However, you do need alignment, empathy, and fewer moving parts. This is especially relevant as many orgs try to copy big-tech frameworks without the organizational muscle to sustain them. Sometimes, a well-documented table with a clear stakeholder is a better data product than an over-templated, underused API.
Before you launch your next “data product initiative,” ask yourself: Is this solving a real problem, or just adding more process? Simplify first, scale later.
From Engineer to Data Leader: How to Actually Lead (Not Just Manage)
Key shifts are required to move from IC to effective data team leader. Yes, you might write less code, but more importantly you’ll own outcomes, align with business goals, and build systems that scale both tech and people. Strategies like setting clear expectations, fostering documentation culture, prioritizing communication, and managing up are essential. It also requires an important shift in mindset: leaders solve problems through people, not just code.
Brilliant data ICs get promoted into leadership only to struggle. Why? Because shipping pipelines isn’t the same as building teams. You’re not always the smartest person in the room anymore, but you’re the one responsible for making the whole room smarter. In mid-size orgs where manager still wear multiple hats, tactical strategies like aligning with stakeholders weekly, thinking in systems, and killing single points of failure are gold for anyone stepping into data leadership.
You can’t scale yourself, but you can scale your team.
Blog Spotlight: SAP Sapphire 2025 Recap: Scaling Smart with SAP’s Business Data Cloud & the Databricks Advantage
There’s a growing synergy between SAP and Databricks as enterprise customers demand tighter integration between business applications and modern data platforms. The standout theme: bringing AI to where the business context lives. SAP is pushing further into AI/ML with Joule and Business AI, while Databricks is emerging as the preferred platform to unlock SAP data for analytics, governance, and GenAI use cases. The partnership signals a strategic shift that moves from isolated SAP silos to open, composable ecosystems that enable real-time decision-making and AI at scale. For data leaders, this means fewer excuses: your ERP data just got a whole lot more usable.
“The world cannot be understood without numbers. But the world cannot be understood with numbers alone.”