- Biweekly Data & Analytics Digest
- Posts
- AI Isn’t Waiting for Your Org to Catch Up, Spark’s Going Real-Time, and Why LLMs Aren’t Actually the Product
AI Isn’t Waiting for Your Org to Catch Up, Spark’s Going Real-Time, and Why LLMs Aren’t Actually the Product
Biweekly Data & Analytics Digest: Cliffside Chronicle
Josh Miramant
27 Aug • Estimated Reading Time: 4 minutes

AI Governance Is Becoming a Hard Requirement
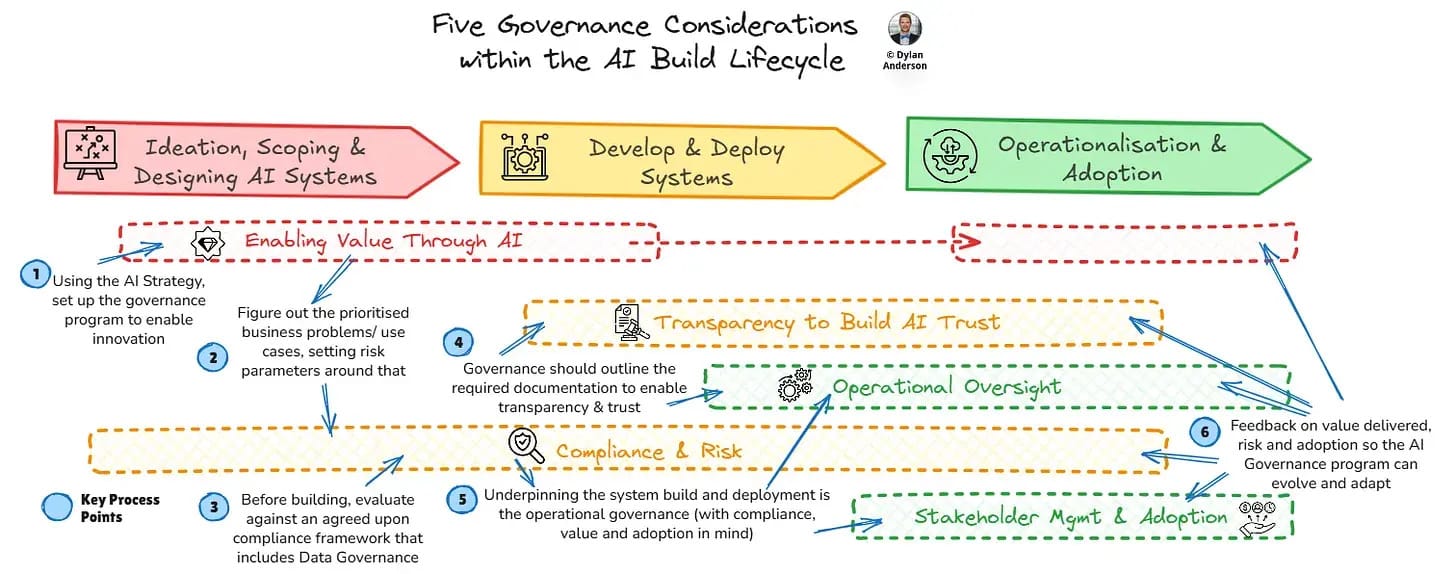
The reality of AI governance is messy because you have to consider model risk, compliance, explainability, privacy, security, and the new headache of vendor accountability. Yes, building AI systems involves GPUs and fine-tuning, but you also need to align with regulators, auditors, and boards who now expect to see concrete guardrails.
Governance used to be a checkbox at the end of a project, but the most forward-looking companies are treating governance like observability: embedded, continuous, and automated. What makes this difficult is the tooling gap. Databricks, Snowflake, and Microsoft are racing to bake governance features directly into their platforms, but most mid-market teams don’t have the luxury of “waiting for the platform.” Instead, they’ll need to blend traditional data governance with AI-specific processes.
The organizations that figure this out early will not only move faster but also avoid the painful “pause everything until we pass audit” scenario.
Stop Treating LLMs Like Products When They’re Just Components

LLMs should be treated as parts of larger systems rather than end-user products. They can be brittle, stochastic, and hard to reason about in isolation, but become powerful tools when used as one building block in a system with guardrails, evaluation loops, and traditional software logic. Think of them less like an application and more like a database: valuable, but only when integrated correctly.
Too many leaders are still asking “what can we build with an LLM?” instead of “what system design problems does an LLM help us solve?” Architecturally, this shifts the focus from chasing magical one-model solutions to designing pipelines that wrap models with retrieval layers, deterministic workflows, and business logic.
The tradeoff is complexity. You need engineers who can reason about distributed systems and failure modes, not just prompt engineers. The payoff is resilience. Your AI features won’t collapse the first time the model hallucinates.
Trust Is the Real GTM AI Feature

Snowflake walks through how they’re building “trustworthy AI” into go-to-market workflows through things like lead scoring, forecasting, and sales enablement. The focus is on reliability, transparency, and human-in-the-loop design. They also emphasize that if GTM teams can’t trust the outputs, adoption could die on the spot. In other words: sales and marketing are unforgiving testbeds for applied AI.
AI governance can feel abstract, but here it’s immediately commercial. If your AI mis-scores leads or generates unexplainable forecasts, your sales team simply won’t use it. Snowflake is smart to anchor trust in both data quality and model design because trust is a distribution advantage.
Embedding governance and reliability directly into applied use cases (not just data platforms) is how you win enterprise adoption. GTM AI should bethe core of how you build and measure success.
Spark Enters the Real-Time Era
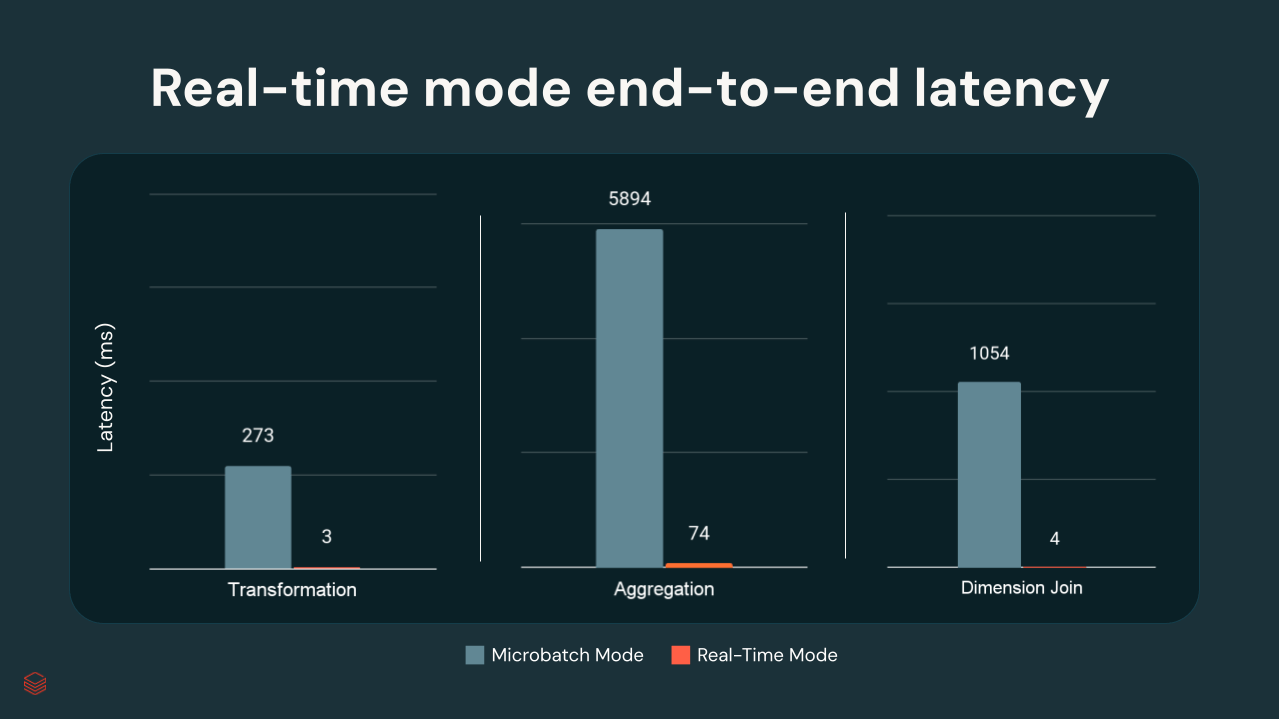
Databricks just announced a new “real-time mode” for Apache Spark Structured Streaming. The idea is to make Spark but competitive with low-latency systems like Flink or Kafka Streams. By cutting micro-batch overhead and simplifying latency-sensitive pipelines, this new mode makes Spark a more viable backbone for use cases like fraud detection, IoT, and real-time personalization.
For years, Spark has been the workhorse of batch and micro-batch analytics, but always carried the reputation of being “not quite fast enough” for true streaming. By pushing Spark into the low-latency space, mid-market teams get the chance to consolidate. Now there’s fewer tools to maintain, one engine that handles batch and real-time, and tighter integration with ML and AI workflows.
You’ll still need to test whether Spark’s real-time mode can hit your SLA compared to Flink or Redpanda, and the operational maturity is unproven at scale. But this is a serious step toward unifying data engineering under one platform.
Making Sense of AI Evals: FAQS Answered by Hamel Husains

If you’ve ever needed a pragmatic walkthrough of AI evaluations (what they are, why they matter, and how to do them without getting lost in jargon), this is for you. There’s an abundance of questions teams actually face: what metrics matter, how to build test sets, when to lean on benchmarks, and where human feedback fits in. But the bigger point is we need to stop thinking of evals as academic exercises about model quality. In reality, they’re guardrails that tell you whether your system will behave the way you need it to once it’s in the wild.
In practice, evals are about operational confidence. Does this model meet business SLAs, avoid failure modes, and improve over time? Databricks and Snowflake are building eval capabilities into their platforms, but most companies can’t wait for perfect tooling when they need lightweight, scenario-specific evals today.
It comes down to rigor vs. velocity. You need to decide if you want to ship quickly with basic evals, or invest in comprehensive pipelines that catch issues earlier. Either way, skipping evals isn’t an option.
AI Coding Is Reshaping Product Management
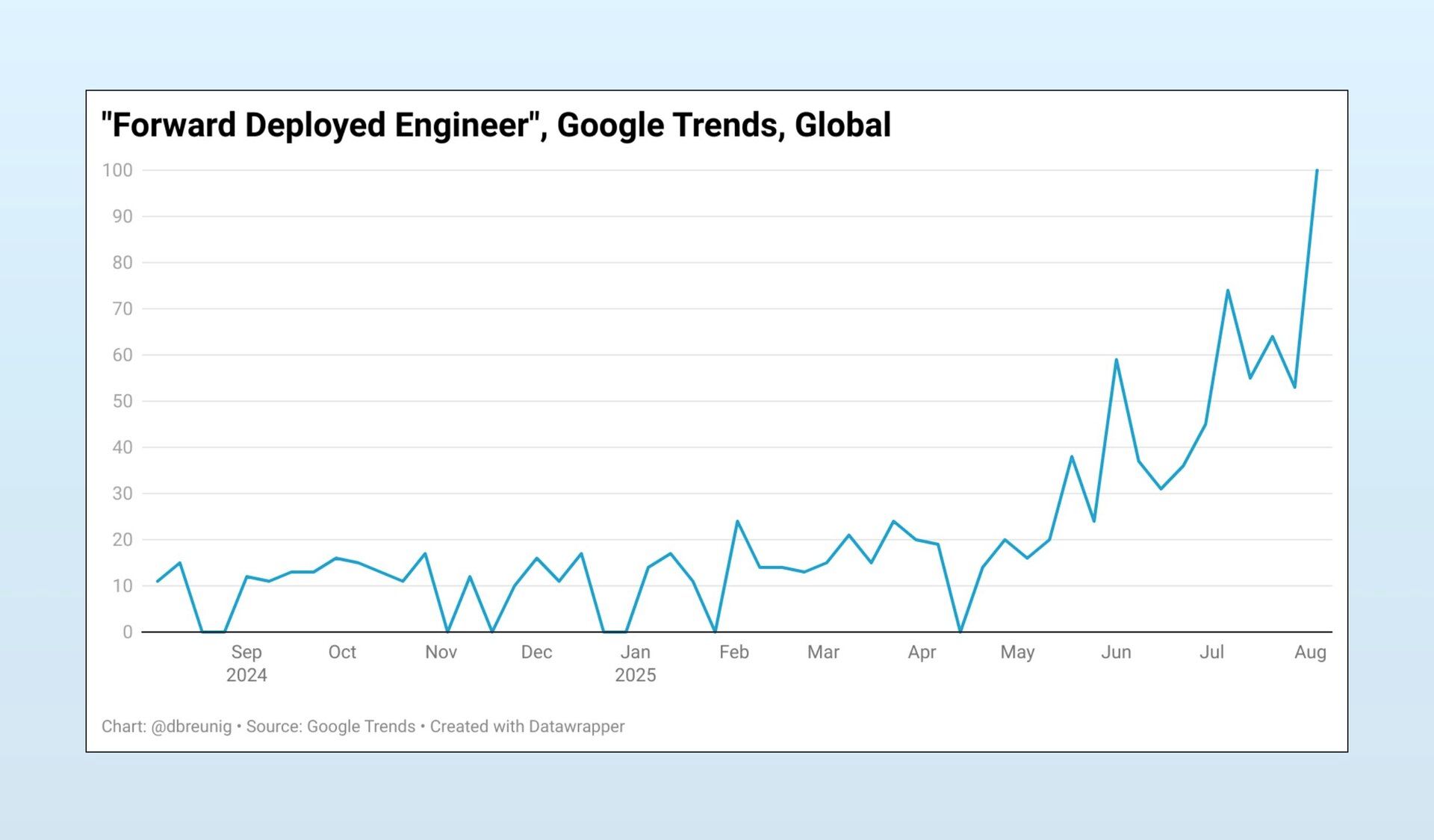
AI-assisted coding will change how engineers write software which means it will also fundamentally alter product management. The traditional PM/engineering relationship will be flipped on its head if AI can generate working prototypes, draft entire features, or explore solution spaces faster than humans. Bottlenecks will shift away from “can we build it?” to “what should we build, and why?”
Right now, most PMs spend a lot of time writing specs, aligning requirements, and negotiating scope with engineers. But if engineers (or even PMs themselves) can spin up functional code via AI, the role of product shifts toward validation, prioritization, and understanding customer needs at a deeper level.
In the end you get speed, but you also risk shipping unvalidated features just because “the AI made it easy.” The orgs that win will be the ones who redesign their product development process around this new dynamic instead of crudely attaching AI coding onto old workflows.
Event Spotlight: Denver Happy Hour
We recently hosted an informal happy hour in Denver with members of the local data and tech community. The conversations covered everything from AI growing pains to scaling analytics in the real world. These are the kinds of insights that rarely show up in scripted presentations, but they drive real impact and connect. We’re planning more of these moments to connect, share, and learn, so stay tuned to hear about future events.
“Data are just summaries of thousands of stories – tell a few of those stories to help make the data meaningful.”